
Here are simple good practices to ensure health of your HDDs, using SMART.
I run a home server since many decades ago with multiple services such as:
- Jellyfin media server
- NextCloud for family file storage
- Samba file server
- Home Assistant for home automation and bridge with Apple Home
- Virtual machines and Podman containers with various other services
Hardware setup is:
- Fedora Linux 40 on Intel NUC11TNBi3 with 16GB RAM and 256GB SSD
- Terramaster D6-320 storage enclosure with 6 SATA HDD, connected to computer by a USB-C cable; no RAID, just a bunch of disks I sporadically add whenever I need more space
- Autorsync daily backup to an old OpenWRT Buffalo router with a 6TB external HDD, located off-site, in the home of a relative
This server is critical for my family, yet several hard drives failed during all these years (that is why I have setup automated backups).
It was not until recently that I learned how to monitor the health of these HDDs using SMART. Get it installed with package smartmontools.

HDD manual health self-tests
When you get a new HDD, after connecting but before putting it into production, you must run a self-health check with command:
smartctl -t long /dev/sdzWhere /dev/sdz is the device name of your new HDD. This test will take more than 10 hours and can be done even with the HDD in use, but it will degrade performance, so I prefer to unmount all filesystems first.
You should run this health check sporadically from time to time.
You can also run 10 minutes health checks without bothering to take your services offline:
smartctl -t short /dev/sdzTo see results of these tests, I prefer using Alexander Shaduri’s GSmartControl GUI, even if smartctl command can also display results. Here is the view of one HDD with the completion status of the health checks we triggered by the smartctl commands above, the Self-Tests tab.
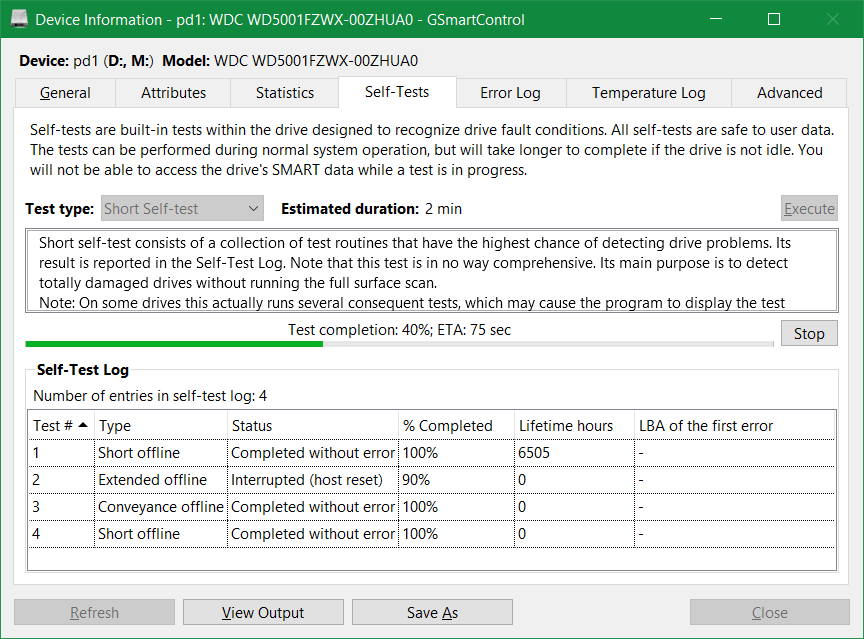
As a general good practice, you must immediately stop using a HDD if you get many errors in the Error Log tab.
SMART error messages are very confusing and proprietary, and I have seen HDDs marked as healthy even if they present many error messages. So again, as a general good practice, if smartctl -l error /dev/sdz output is very long and is not a simple No errors logged, it is time to migrate data off of the HDD and replace it.
Automated health tests
The smartmontools package also installs a service that checks HDD health daily and sends a report by e-mail. On Fedora Linux this is activated by simply installing the package, but is useless if your system can’t send e-mails, which is the way reports are delivered. So make sure you enable your server to send e-mails. There are many ways of doing this, the simplest one is using Gmail as relay.
If your HDD is starting to fail, you’ll get an e-mail from the SMART daemon. If that happens, you must run more extensive health checks as described above. And check your backups and move your data off of the failing HDD.
Also, you should check the warranty of your HDDs. The more premium product lines of Seagate (IronWolf) and Western Digital (Red) offer 3-year warranty and you should make sure you’ll get these when you buy it. Use your HDD serial number to check if warranty coverage is still valid on Seagate and Western Digital websites. You can fill some forms on the manufacturer’s website to get a brand new replacement HDD.
One thought on “Ensuring health of your NAS hard drives with SMART”