Since we got a 52″ Samsung LCD TV almost a year ago as a gift from relatives, I knew it was time to attach to it a dedicated computer and have a full digital media experience in the living room. I’ll tell you here my experiences building and running this thing that makes all my guests very impressed and desiring one.
 Things you can do with a Media Center
Things you can do with a Media Center
- Play all your digital music (MP3, M4A, FLAC etc) as albums, custom play lists or randomly.
- Browse all your digital music semantically, by Genre or Artist or Song Name or Album. This is very practical and much faster than searching for a CD on your shelf.
- Tune hundreds of Internet radios that play all kinds of specific music as New Age, 80’s, 70’s, Classical, Flamenco, etc.
- Watch movies downloaded from the Internet in Full HD quality (1080p) or almost (720p) with or without subtitles. Who needs Blu-ray ?
- Play last trip photos as a slideshow in a 52″ TV. Who needs to develop photos in paper anymore? You can also play in the background music from your MP3 collection while watching the slideshow.
- Browse photos by trip, year and people that appear on them (if you tag them).
- Watch in a 52″ TV the clips from your last trip.
- Download a collection of 80’s music clips, invite your friends and make a very funny multimedia 80’s party.
- Watch YouTube videos in a 52″ TV.
- Browse Google Maps in 52″ TV.
- Control all the above using a nice handy $20 remote control.
- Let your iPhone/iPod browse, access and play all your music as it is loaded on your iPhone, through UPnP and PlugPlayer.
How to build a Media Center
Its easy and cheap to build a Media Center. In fact, the most expensive component is the TV, not the computer. You can do it with whatever operating system you like: Linux, Windows Vista or Mac. I wanted to do it with Linux because I am more fluent with this platform, but I had to use Vista because Linux audio drivers for my computer were not ready at that time. I’ll put bellow all the conceptual components in an modular way so you can understand what is important on each. But usually you will find them together in a single board very well integrated. In fact, unless you know what you are doing, I recommend using integrated components as motherboards that have a good GPU plus audio integrated in a single HDMI output connector.
The physical ingredients to build a Media Center are:
- An LCD TV. Looks like Plasma is an obsolete technology but I’m not the right person to ask about that. An LCD or Plasma TV is a plain big computer monitor, there is no big differences when compared to the computer monitor you are using right now to read this. Make sure the TV you buy has HDMI input connector, is Full HD (that is, its physical resolution goes up 1920×1080 (a.k.a. 1080p) or more) or at least is Full HD Ready (its maximum physical resolutions is less than 1920×1080 but can handle 1920×1080 signals with distortion), has a VGA input connector and a stereo audio input connector.
- A regular dedicated computer with at least a dual core CPU and 2GB RAM. This will be connected to the TV and forget about using it as a regular desktop. Intel or AMD will do here. If you will play only those low-quality, old, 700MB DivX/Xvid files, a generation before dual core (as AMD Turion) will do, but if you are going to enter the HD world with H.264 (a.k.a x264), MP4, MKV, you’ll need at least 2 cores. About the 2GB RAM, this is a guess and you may play well with a bit less too, but never tested. My system is a Quadcore AMD Phenom, 4GB RAM (because I use it for other purposes too) into a XFX 8200 HDMI-enabled motherborad (this board has unsolved issues with audio over HDMI and high power CPUs, thus I would recommend you look for another brand or model).
- A video card/chip that can go up to 1920×1080 resolution with DVI or HDMI output connector. People keep saying that you need NVidia and this is a lie, let me explain. NVidia or ATI GPUs (graphical processing units) have capabilities and hardware accelerators used by advanced 3D games, not by video players. So unless you are going to use this PC also as an advanced playing station, any GPU (a.k.a. graphic card/chip) will do the job, including those very popular Intel GPUs found on board in laptops. Just make sure to configure your BIOS and set video RAM to the maximum, otherwise you will have video delay problems playing Full HD (1080p) videos. If the video card only has VGA output, thats fine too but be aware that you’ll need extra cables for audio. Read next item to understand.
- An audio card that outputs 7, 8 or 13 channels of sound. Stereo (2 channels) is old school. Today’s any regular DVD has 5.1 (6 channels) surround audio (2 front, 2 rear, 1 center and 1 sub-woofer) and you want to take advantage of that. This is today very common and easy to find in stores, just make sure this component is integrated with the video component above and both use one single HDMI output connector.
- Remote Control. Your folks will call you a complete geek if they’ll see you browsing photos and music with a keyboard and mouse. Out of fashion. I bought a simple but effective infrared remote control that has a receiver that plugs into the USB for about $20. It has specific buttons for Pictures, Video, Music and works well with Vista Media Center.
- Lots of storage. If you are going to collect HD movies, rip DVDs, store photos and rip all your CDs, start with at least 1TB hard drive. Also make sure you have internal space in your computer to receive additional hard drives because you will run out of space sooner or latter. Another option is to have a motherboard with external SATA connectors (similar to USB connectors) and connect external SATA hard drives for increased speed and flexibility. An example of such an external SATA storage is Sagate’s FreeAgent XTreame.
- A silent power supply. Nobody thinks about that but I believe this is very important. Since this PC will stay in your living room or some place for multimedia contemplation, you don’t want to be disturbed by the computer’s fan noise while listening to your collection of zen Ambient music. Spend a few dollars more and make sure your power supply is quiet. I am a happy and zen user of a 450W Huntkey power supply.
- HDMI cable. This is the single cable you should use to connect the Media Center PC to your TV. This single cable should carry Full HD video and 13 channels audio, it should costs $20 and is a clean and modern solution.

These are the aproximate brazilian prices I pay for the hardware parts
| Description | Part Number | Price US$ |
| Motherboard XFX 8200 GeForce | MI-A78S-8209 | $172.22 |
| AMD Phenom Quadcore 9750 | HD9750WCGHBOXSN | $338.89 |
| Seagate Barracuda 750GB | 9BX156-303 | $205.56 |
| 4GB RAM | $133.33 | |
| HUNTKEY Power supply 14CM EPS12V | LW-6450SG 450W | $94.44 |
| HDMI cable | $16.67 | |
| Nice PC case | $138.89 | |
| Gotec Remote Control 3801 for Media Center | $26.61 | |
| Total | $1,126.61 | |
Home Networking
You may want to have Media Center(s) in several spots of your home playing media from a central network file server located somewhere else.
You should pay attention to not overload your home wireless network. I had bad experiences streaming HD media from one computer to another over WiFi. A single wall in between can dramatically decrease the kilobits per second the wireless signal can carry, to a level that is lower than your movie’s kilobits per second. The result are unwatchable movies while streaming. Big photos will also take longer to load to a point that will affect negatively your ambient slideshow.
To avoid that:
- Have your files physically connected to your Media Center. This can be a plain internal disk (this is my choice) or an external SATA or FireWire or USB attached disk. Remember that USB is much slower (even than FireWire) and file transfers (as copying lots of movies to/from a frined) will take longer time.
- Have a separate file server but connect it to your Media Center over a wired network.

Software Requirements
Your Media Center will have several simultaneous purposes. The most visible one is to feed your TV with content, but I also use it as a host to run several virtual machines, a web server, file server and to download things. I use mine 40% as a visible Media Center, 30% as a Media Server (to serve media to other computers) and 30% as a host for other purposes.
Forget about using your Media Center as a regular PC with keyboard and mouse. It is simply not practical and will prevent your wife and kids to use it because you are locking its TV. You can connect to and work with it remotely though, with SSH, VNC, Desktop Sharing, Remote Desktop or whatever technology your platform supports. And this can happen while your folks are watching a movie. I found this way of managing my Media Center very practical and productive.
- Linux-based Media Center
Linux would be my preferred platform for running a Media Center. It is highly configurable and gives its owner a lot of power. To feed your TV, use MythTV or XBMC. Just make sure that devices as remote control, audio and HDMI interface have drivers and will work on Linux. I had problems with that.
- Mac OS-based Media Center
If you are an Apple person, a Mac mini will do the job. It is compact, silent, has a strong enough processor and comes with a nice remote control. If Mac OS is your platform of choice, use FrontRow or XBMC. You will also need a codecs to play all types of media, so download the free Perian codec pack. I don’t know much people that use Mac OS as a Media Center, let me know if you do. You can also use an Apple machine to run Windows.
- Windows Vista-based Media Center
Windows Vista has a lot of improvements for managing media when compared to Windows XP. The native File Explorer support for MP3 and photo tagging is excelent, uses open standards as ID3v2 (MP3) and EXIF and IPTC (JPEG photo) and Vista Media Center has partial support for browsing you media collection through these tags (album, artist, genre, date picture was taken, IPTC tags etc). Strangelly, Vista Media Center does not support browsing by multiple genres and multiple artists so an album simultaneously tagged with genres “Samba” and “MPB” will appear only when you list by “Samba”, not by “MPB”.
Microsoft locks their desktop operating systems in a way that multiple users can’t use it simultaneously, even if there are multiple users created on the OS. This can be fixed installing a small terminal services-related patch. There is also a post-SP1 version of the hack.
So the modus operandi is to create one user called Media that will automatically login and run the Media Center program at boot, and another one for me to login remotely with Remote Desktop and run stuff simultaneously. The Media user has to be administrator and codec packs and plugin must be installed by him.
To play advanced and HD audio and video, H.264, MKV, MP4, DivX/Xvid, FLAC etc, you will also need a codec pack for Windows. I recommend the K-Lite Codec Pack and I use its Mega edition. Having that, Vista Media Center will play any type of media.
I must tell that Windows alone can’t satisfy all my media management needs. Thats why I run a Linux as a virtual machine on the Media Center to make massive manipulations of MP3, photos, video compression, etc.
Still on Vista Media Center, I use several useful plugins:
- Media Control. Improves usability of the remote control and lets you set subtitle and audio languages, enables fast forwarding etc while playing video.
- Google Maps for Windows Media Center. Turns my 52″ TV into an interactive map that I can control with my remote control. I don’t know how life was before this.
- Yougle. Lets you access Internet media from Vista Media Center. In other words, lets you browse and watch YouTube videos, Flickr photos, Internet radios etc.
Happy entertainment !


 Os 63 comentários foram lidos na parte da manhã e gastamos quase a tarde inteira para discutir calorosamente somente um dos 2 comentários polêmicos. Soa como discutir o sexo dos anjos: ninguém parece estar errado nem certo.
Os 63 comentários foram lidos na parte da manhã e gastamos quase a tarde inteira para discutir calorosamente somente um dos 2 comentários polêmicos. Soa como discutir o sexo dos anjos: ninguém parece estar errado nem certo.

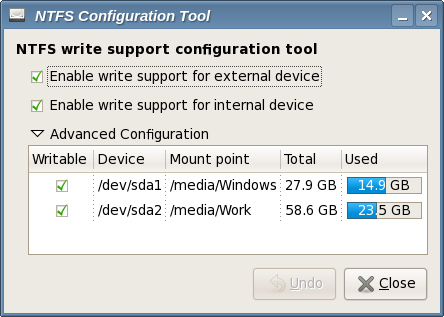
 A Nokia não me pagou para dizer isso, mas com certeza meu próximo celular será um smartphone desse fabricante, da linha N ou E.
A Nokia não me pagou para dizer isso, mas com certeza meu próximo celular será um smartphone desse fabricante, da linha N ou E.
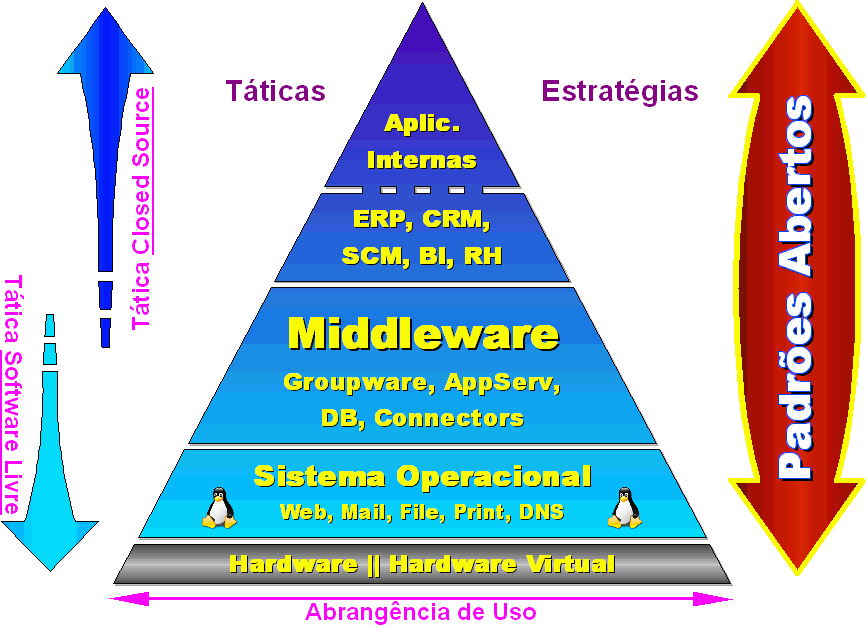


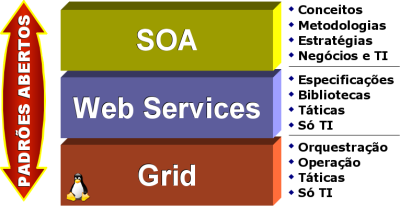
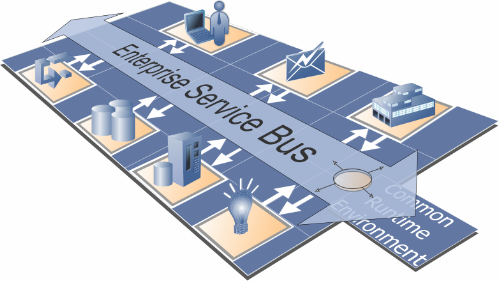
 Existem hoje inúmeros Padrões Abertos, mas os que se destacam são os seguintes:
Existem hoje inúmeros Padrões Abertos, mas os que se destacam são os seguintes: