Some friends asked so the following is how I encode (rip) DVDs.
Choosing the file format: .AVI, .OGG, .MP4 or .MKV ?
The ripped video file format is a decision you must make. Currently my format of choice is .MKV or Matroska. I’ll explain why.
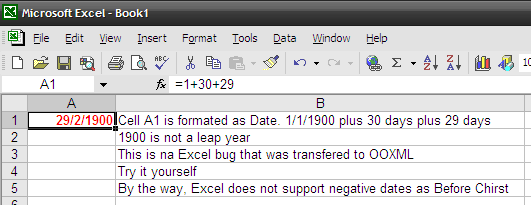
It is quite silly to say that an .MP4 movie has better quality than a .AVI or vice-verse (or any other combination of comparisons). OGG, MP4 (MPEG-4 Part 14), MKV (Matroska), AVI, WMV (or ASF) are just containers, envelopes. Video quality depends on what goes inside it.
“Multimedia” has this name because you have multiple types of media: video in multiple angles, multiple audio options including different languages and channels (stereo, 5.1, 6 channels etc), subtitles in several languages, chapter information, menu etc. Think about a DVD. So this is a graphical view of how things are organized inside a 900MB movie file in a modern format as MKV or MP4:
| Header with tags, track names, chapters info, seek positions |
Main Video track (MPEG-4 AVC/H.264) |
Attachments as JPG images, documents, scripts or text files |
|
Video segment showing another angle (MPEG-4 ASP/Xvid/DivX) |
|
| Audio track: English Dolby Surround 5.1 (AC3) |
| Audio track: Director’s comments stereo (MP3) |
| Audio track: Portuguese Dolby Surround 5.1 (DTS) |
| Subtitle track: Portuguese (Unicode text) |
| Subtitle track: Chinese (Unicode text) |
| Subtitle track: English (VobSub) |
| byte 100K |
byte 100M |
byte 200M |
byte 310M |
byte 420M |
byte 530M |
byte 650M |
byte 780M |
byte 895M |
byte 900M |
A digital multimedia file format must be capable to contain all this different medias and multiplex them in parallel so you won’t have the video in the first 500MB of the file and the audio on the following 500MB (this can’t work for streaming). And this is exactly what modern file formats as MP4 and MKV do: they carry all your movie-related data together.
This is a comparison of all these file formats based on my personal experience with them (a more formal comparison can be found in Wikipedia):
|
.MKV |
.MP4 |
.AVI |
| Industry support |
Almost none |
Good and increasing, specially on Apple platforms, the mobile scene and Nero Digital ecosystem |
Treated as legacy popular format |
| Usage on the web |
Very popular on HD or high quality DVD rips |
Very popular on HD or high quality DVD rips, supported by Flash Player, YouTube, Google Video |
Popular amongst low-quality DVD rips |
| Support for advanced video formats and multiple video angles |
Yes. MPEG-4 ASP (DivX, Xvid), MPEG-4 AVC (a.k.a. H.264) etc |
Yes. Only MPEG-4 systems and a few others |
Problematic and No |
| Support for multiple audio tracks (channels, formats, languages and “director’s comments”) |
Yes |
Yes. Formats are only MP3, AAC and a few others not very popular |
Yes |
| Support for tags (artist, title, composer, etc as MP3’s ID3) |
Yes |
Can be supported by MP4 extensibility but this is not very well standardized across authoring tools (iTunes, GPAC etc) and players (Amarok, Media Player Classic, iPod, Windows Media Player etc) |
No |
| Support for attachments with mime-types (used to attach movie posters images or other files) |
Yes |
No |
| Support for chapter marks |
Yes |
No |
| Support for multiple language embedded soft-subtitles |
Yes. VobSub (as extracted from DVDs), plain timed UTF-8 text (SRT, SUB) etc |
No |
| Support for naming tracks with human names as “Director’s comments” or “Portuguese subtitles” etc |
Yes |
Yes |
No |
| Support for carrying menus information (as in DVDs) and interaction |
Yes through an XML idiom, but unsupported by most players |
Yes through SVG, but unsupported by most players |
No |
| The container overhead in bytes in the final file |
Very small |
Very small |
Very big |
| Supported by free and Open Source multiplatform authoring tools |
Perfect on Linux, Unix, Windows and Mac |
Yes (see GPAC), with some intellectual property issues. Tools need to mature. |
Yes |
| Ready for popular web streaming as in Flash player |
No |
Yes. The popular Flash Player that is installed on everybody’s browser supports playing MP4 files as long as they contain H.264 video and AAC audio tracks. I recommend the LongTail FLV/MP4 Player since it also plays subtitles embedded in MP4 files. |
No |
Personally I believe MP4 is the multimedia file format for the future because since it is getting popular, all these non–standardized features will get stabilized. MP4 is an ISO standard and the increasing industry support can be felt on iPods and portable devices, and most notable on home DVD players capable of playing the 700MB MP4 video file burned in a CD.
By the way, remember this:
- MP4 is not an evolution of MP3. AAC (MPEG-4 Part 3) is.
- MP5 and MP6 (used to classify portable media players) are things that simply doesn’t exist in the multimedia scene.
- .M4A, .M4V, .MOV and .3GP files can safely be renamed to .MP4. They just use to be different extensions to help user’s eyes easily identify whats inside.
Meanwhile, MKV wins everything but on the Industry Support category. But this doesn’t really matter, and I’ll explain why. Since MKV is just a container, the large video, audio etc streams can be extracted and repackaged into MP4 and vice-versa in seconds. No transcoding (decoding followed by a lossy encoding into another format) is needed.
So today I store my videos in the most feature rich and well supported by players format: MKV.
OGG or OGM (the container file format) is practically dead in my opinion. They were created as part of the Xiph initiative for a complete open source patent-free multimedia framework, but seems nobody uses it anymore for video. From the same family, Vorbis (the audio codec compared to MP3, a.k.a. .OGG) is very good but also very not popular. Theora (the video codec) is frequently comparable to old MPEG-1 in terms of quality and compression ratio so currently, if you want quality and are not concerned about patents, MPEG-4 AVC is the best choice. FLAC, Xiph’s lossless audio codec, is the winner of the family: very popular, massively used, and recommended.
Encoding the DVD
I use HandBrake, the most practical Open Source (and overall) movie encoder. It runs on Linux, Mac and Windows and uses the same Open Source libraries as ffmpeg, mplayer/mencoder, xine, etc. While these programs are generic video handlers (with thousands of confusing configuration parameters to sustain this generalistic status) HandBrake is optimized only for ripping so it is very easy to use, yet extremely powerful.
#!/bin/bash
##
## This is the script I use to make hifi DVD rips including chapter markers and
## subtitles. It uses Handbrake.
## Contains what I found to be the best quality ripping parameters and
## also let me set simple parameters I need.
##
## Avi Alkalay <avi at unix dot sh>
## http://avi.alkalay.net/2008/03/mpeg4-dvd-rip.html
##
## $Id$
##
#set -vx
HANDBRAKE=${HANDBRAKE:=~/bin/HandBrakeCLI}
#HANDBRAKE=${HANDBRAKE:="/cygdrive/c/Program Files/Handbrake/HandBrakeCLI.exe"}
## Where is the Handrake encoder executable.
## Handbrake is the most practical free, OSS, DVD riper available.
## Download HandBrake for Linux, Mac or Windows at http://HandBrake.fr
INPUT=${INPUT:=/dev/dvd}
## What to process. Can also be a mounted DVD image or simply '/dev/dvd'
TITLE=${TITLE:=L}
## The title number to rip, or empty or "L" to get the longest title
#CHAPTERS=${CHAPTERS:=7}
## Example: 0 or undefined (all chapters), 7 (only chapter 7), 3-6 (chapters 3 to 6)
#VERBOSE=${VERBOSE:="yes"}
## Wether to be verbose while processing.
SIZE=${SIZE:=1200}
## Target file size in MB. The biggest the file size, the best the quality.
## I use to use from 1000MB to 1400MB for astonishing high quality H.264 rips.
OUTPUT=${OUTPUT:="/tmp/output.mkv"}
## Output file. This will also define the file format.
## MKV (Matroska) is currently the best but MP4 is also good.
AUDIO=${AUDIO:="-E ac3 -6 dpl2 -D 1"} # For AC3 passthru (copy).
#AUDIO=${AUDIO:="-E lame -B 160"} # For MP3 reencoding. Good when input is DTS.
## Audio parameters. If input is AC3, use it without transcoding.
## If is DTS, reencode to MP3.
MATRIX=${MATRIX:=`dirname $0`/eqm_avc_hr.cfg}
## x264 matrix to use. The matrix file may increase encoding speed and quality.
## This one is Sharktooth's as found
## at http://forum.doom9.org/showthread.php?t=96298
######### Do not change anything below this line ##############
## Make some calculations regarding title and chapters based on parameters.
SEGMENT=""
if [[ "$TITLE" == "L" || -z "$TITLE" ]]; then
SEGMENT="-L"
else
SEGMENT="-t $TITLE"
fi
[[ -n "$CHAPTERS" && "$CHAPTERS" -ne 0 ]] && SEGMENT+=" -c $CHAPTERS"
[[ "$VERBOSE" != "no" ]] && VERB="-v"
# Define args for the x264 encoder. These are some values I found on the net
# which give excelent results.
X264ARGS="ref=3:mixed-refs:bframes=6:b-pyramid=1:bime=1:b-rdo=1:weightb=1"
X264ARGS+=":analyse=all:8x8dct=1:subme=6:me=umh:merange=24:filter=-2,-2"
X264ARGS+=":ref=6:mixed-refs=1:trellis=1:no-fast-pskip=1"
X264ARGS+=":no-dct-decimate=1:direct=auto"
[[ -n "$MATRIX" ]] && X264ARGS+=":cqm=$MATRIX"
# Encode...
"$HANDBRAKE" $VERB -i "$INPUT" -o "$OUTPUT" \
-S $SIZE \
-m $SEGMENT \
$AUDIO \
-e x264 -2 -T -p \
-x $X264ARGS
# Repackage to optimize file size, to include seek and to include this
# this script as a way to document the rip...
echo $OUTPUT | grep -qi ".mkv"
if [[ $? && -x `which mkvmerge` && -f $OUTPUT ]]; then
mv $OUTPUT $OUTPUT.mkv
mkvmerge -o $OUTPUT $OUTPUT.mkv \
--attachment-name "The ripping script" \
--attachment-description "How this movie was created from original DVD" \
--attachment-mime-type application/x-sh \
--attach-file $0
[[ -f $OUTPUT ]] && rm $OUTPUT.mkv
fi
The script seems long because it is fully documented but it actually only collects some parameters and simply runs the HandBrake encoder like this (passed parameters are in red):
~/bin/HandBrakeCLI -v -i /dev/dvd -o /tmp/output.mkv \
-S 1200 \
-m -L \
-E lame -B 160 \
-e x264 -2 -T -p \
-x ref=3:mixed-refs:bframes=6:b-pyramid=1:bime=1:b-rdo=1:weightb=1:analyse=all:8x8dct=1:subme=6:me=umh:merange=24:filter=-2,-2:ref=6:mixed-refs=1:trellis=1:no-fast-pskip=1:no-dct-decimate=1:direct=auto:cqm=~/src/randomscripts/videotools/eqm_avc_hr.cfg
All the rest is what I found to be the best encoding parameters.
The resulting video file (/tmp/output.mkv in this case) will contain correctly cropped video and audio quality as good as the DVD (it is almost lossless), and chapter breaks at the same positions read from the DVD.
In a Core Duo machine as my laptop running Fedora 8 or Windows XP, a 2 pass H.264 encoding (2 pass improves quality and H.264 is newer standard MPEG-4 technology better than DivX/Xvid) takes about 4 to 5 hours for a regular 2 hours movie, so leave it encoding while you go to sleep. A Pentium 4 machine running Ubuntu takes about 17 hours for the same rip.
I use to rip one chapter from the movie first (use your preferred video player or lsdvd command to find the shortest chapter), check quality, compare to DVD, fine tune, try again and then shoot full DVD ripping.
After encoding I use to repackage the audio/video stream with Matroska‘s mkvmerge (or mmg, its GUI version available on any Linux distribution as “mkvtoolnix” package, and installable for Windows or Mac OS from Matroska’s website) to optimize seeks and to include soft subtitles (that can be turned on and off as on regular DVDs), but I’ll explain that in another HOWTO.
Give Your Ripped Movie a Descriptive File Name
I use to organize my media library in a standard way I invented for myself and which I suggest you to use too.
My movie file names shows everything that the file includes. Some examples:
- Indiana_Jones_and_The_Raiders_of_the_Lost_Ark_IMDB{tt0082971}-Xvid{720x304_23.98fps}+MP3{ENG,POB_VBR}+Sub{ENG,SPA,POB}+Covers.mkv
This is the Indiana Jone’s Raiders of the Lost Ark movie, whose IMDB index is tt0082971 (IMDB{tt0082971}). It was ripped with the old Xvid codec and contains 720×304 pixels frame size at a rate of 23.98 frames per second (Xvid{720x304_23.98fps}). It also contains selectable audio tracks in English and Brazilian Portuguese encoded in variable bit rate MP3 (MP3{ENG,POB_VBR}). In addition, there is also selectable subtitles in English, Spanish and Brazilian Portuguese (Sub{ENG,SPA,POB}). The file also contains the cover images as attachments.
- Harold_and_Maude_IMDB{tt0067185}-H264{672x368_3Pass_25fps}+HEAAC{EN}+Sub{POR,EN,FRE}+Chapters+Covers.mkv
The old Harold and Maude movie whose IMDB index is tt0067185 (IMDB{tt0067185}). It is encoded with H.264 in 3 passes and has 672×368 pixels frame size at a rate of 25 frames per second (H264{672x368_3Pass_25fps}). There is only one English audio track encoded in modern HE-AAC (HEAAC{EN}). Subtitles in Portuguese, English and French (Sub{POR,EN,FRE}), chapter information and attached cover images. This is very complete high quality DVD backup.
- I_Am_Legend_IMDB{tt0480249}-H264{704x304_23.98fps}+AC3{ENG_5.1}+Sub{POR}.mkv
The I Am Legend movie whose IMDB index is tt0480249 (IMDB{tt0480249}), video encoded in H.264 with 704×304 pixels frame size (H264{704x304_23.98fps}), original 5.1 channels AC3 audio in English (AC3{ENG_5.1}) and subtitles in Portuguese (Sub{POR}).
The advantages of this scheme are:
- It is web safe with no spaces in filenames. All underlines. It is also DOS safe.
- To have the IMDB index let me know exactly which movie this file contains. This is particularly good to avoid ambiguity for movies that have remakes as Ben Hur, or movies that have an official name but are well known by other names or have international titles.
- To know the encoding method, subtitles included and chapters info give me the overall quality of the movie right away.
- Special attention to audio and subtitle languages. Having them on the filename let me know I will understand its content without having to play. Sometimes I can’t play the file because I logged in my home computer remotely.
Playing the Ripped File
To play this advanced Matroska media file that contains such a rich set of metainformation and highly compressed digital content you will need an advanced player too. And happens that the best players are the Open Source ones. So use these players:
These are Media Player Classic screenshots demonstrating how to activate the advanced content inside a Matroska file. Players on other platforms have similar capabilities and menus.
Activating embedded subtitles and languages
The player lets you choose the audio language and subtitles. On MPC for example, this is how you turn on and off and choose the language for subtitles.

As you can see, the player found subtitles embedded in the MKV file in English, Hebrew and Portuguese.
If the MKV file contains many audio tracks (as different languages, director’s comments etc) this is how to select it:

And to jump directly to a specific chapter on the movie, if the MKV file contains this kind of information:

Improving audio volume
If you ripped the movie without reencoding the audio, the final file will contain DVD’s original AC3 audio tracks in 6 channels (5+1). This may sound with a lower volume when played in a 2-speaker system as your laptop, iPod, etc because 4 channels are simply not being played. To remediate this the player will have to downsample the audio. In other words, it will remix the 6 channels into 2 stereo channels while playing. The Media Player Classic options should look like this:
















 Essas
Essas